So, Apache Spark is getting popular and I’m starting to get a hang of it. Our team uses Databricks, and I found it (and the whole concept of notebooks) great for small things. However, when it comes to writing more complex programs, I’m very much used to convenience of IntelliJ for writing, testing and refactoring the code. Moreover, the new Dataset[T] API allows you to rely on type safety and depend much less on constant re-runs.
Step 1: Connect with Databricks
Create a simple SBT project and add sbt-databricks plugin to the project, access details should be specified in build.sbt.
In build.sbt you should have somthing like:
name := "databricks-test"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.0.0"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.0.0"
dbcUsername := "myself@example.com" // Databricks username
dbcPassword := "verysecret" // and password
// The URL to the Databricks Cloud API!
dbcApiUrl := "https://community.cloud.databricks.com/api/1.2"
dbcClusters += "My Cluster" // Where your stuff should be run
dbcExecutionLanguage := DBCScala // Language
dbcCommandFile := baseDirectory.value / "src/main/scala/mean.scala"
the last settings points to a Scala script. Create it and let’s start coding.
Step 2: Write
There are several things like sc: SparkContext that are globally available in Databricks. IntelliJ doesn’t have a clue about those, so to have a nice autocompletion we need to do something about it. I’ve found this pattern pretty handy:
import org.apache.spark.SparkContext
import org.apache.spark.sql._
def run(sc: SparkContext, ss: SparkSession) = {
import ss.implicits._
val numbers: Dataset[Int] = Seq(1, 2, 3).toDS()
val doubled: Dataset[Int] = numbers.map(_ * 2)
println("=== The new dataset is: ====")
doubled.show()
println("=== Mean of the new dataset is: ====")
println(doubled.reduce(_ + _) / doubled.count())
}
run(sc, SparkSession.builder().getOrCreate())
The last line will contain an unresolved variable, but the rest of the code will be treated as valid.
Step 3: Run
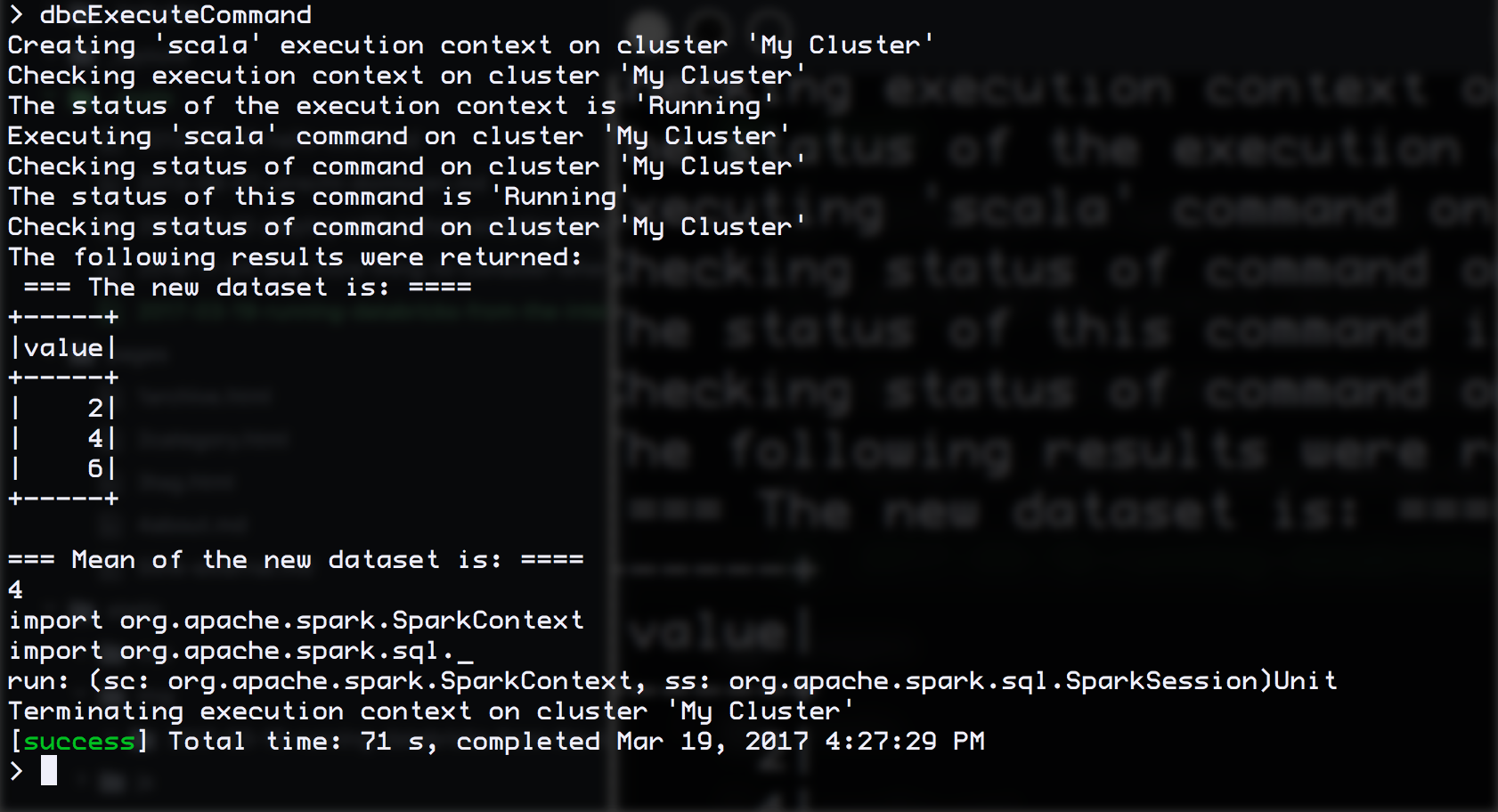
Hit dbcExecuteCommand in sbt console, and you should see something like like this: